En este proyecto realicé la limpieza y preparación de un dataset de análisis de riesgo crediticio de clientes bancarios. El objetivo fue dejar los datos listos para futuros modelos de predicción de riesgo, corrigiendo valores nulos, duplicados y formatos inconsistentes. Entre los principales hallazgos destacan variables con alta cantidad de datos faltantes y patrones relevantes en el comportamiento crediticio.

- Se importaron librerías esenciales para manipulación, visualización y modelado: pandas, numpy, matplotlib y scikit-learn.
- Se cargó el conjunto de datos desde Google Drive utilizando Google Colab.
Librerías usadas
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
Carga de datos
# Conexión con la base de drive
from google.colab import drive
drive.mount('/content/drive')
# Creación de data frame
datos_respaldo = pd.read_csv('drive/MyDrive/Colab Notebooks/Análisis de riesgo en banco/lendingclub.csv')
datos = datos_respaldo.copy()
pd.options.display.max_columns = None
datos.tail(2)
Analisis exploratorio general
datos.info()

Tomar del df datos solo las columnas esenciales para el modelo
# Se omiten las columnas vacías y aquellas donde faltantes son mas del 60%
df_predict = datos[["loan_status", "loan_amnt", "funded_amnt", "int_rate", "installment", "term",
"emp_length", "home_ownership", "annual_inc", "dti", "open_acc", "revol_bal",
"revol_util", "delinq_2yrs", "inq_last_6mths"]]
df_predict.head(4)

Cambia el nombre a las columnas para hacerlo entendible para todos
df_predict = df_predict.rename(columns={
"loan_status": "estados_prestamo",
"loan_amnt": "monto_prestamo",
"funded_amnt": "monto_financiado",
"int_rate": "tasa_interes",
"installment": "pago_mensual",
"term": "plazo_meses",
"emp_length": "anios_experiencia",
"home_ownership": "tipo_vivienda",
"annual_inc": "ingreso_anual",
"dti": "relacion_deuda_ingreso",
"open_acc": "cuentas_abiertas",
"revol_bal": "saldo_tarjetas",
"revol_util": "uso_credito",
"delinq_2yrs": "moras_ultimos_2_anios",
"inq_last_6mths": "consultas_credito_6_meses"
})
# Verificar cambios
df_predict.head(3)

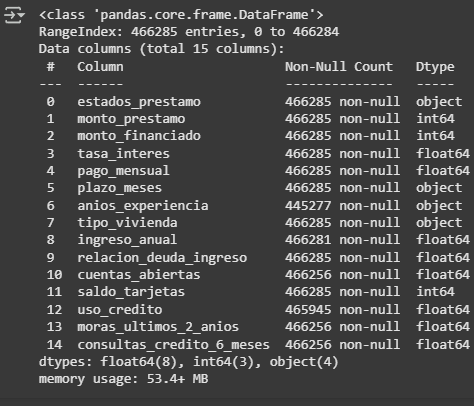
Revisión de faltantes en columnas
df_predict.info()
Transformación entre deudores y no deudores
df_predict["estados_prestamo"].unique()

df_predict["estado_prestamo"] = df_predict["estados_prestamo"].map({
"Fully Paid": 1,
"Does not meet the credit policy. Status:Fully Paid": 1,
"Current": 1,
"Charged Off": 0,
"Default": 0,
"Late (31-120 days)": 0,
'In Grace Period': 0,
"Late (16-30 days)": 0,
"Does not meet the credit policy. Status:Charged Off": 0
})
df_predict["estado_prestamo"].unique()

Quitar un texto que está demás
# Limpieza del campo
df_predict['plazo_meses'] = df_predict['plazo_meses'].str.replace('months', '').astype(int)
# Ver los valores únicos
df_predict['plazo_meses'].unique()

df_predict['anios_experiencia'].unique()

# Quitar textos innecesarios
df_predict['anios_experiencia'] = df_predict['anios_experiencia'].str.replace('+ years', '') \
.str.replace('years', '') \
.str.replace('< 1 year', '0') \
.str.replace('year', '')
# Rellenar nulos con 0
df_predict['anios_experiencia'] = df_predict['anios_experiencia'].fillna(0).astype(float)
# Ver los valores únicos
df_predict['anios_experiencia'].unique()

df_predict.dropna(inplace=True)
- Se realizaron visualizaciones con seaborn y matplotlib:
Boxplots segmentados por estado del préstamo.
Gráficos de dispersión para observar relación entre deuda, ingresos y moras.
Histogramas de distribución de variables numéricas.
- Se detectaron outliers y sesgos en los datos.
- Se observó que factores como la relación deuda-ingreso, experiencia y propósito del crédito son relevantes.
Columnas usadas
df_predict.columns

Distribución de Montos y Pagos (Histograma); Relación Monto del Préstamo vs Ingreso Anual (Scatter Plot)
## Crear gráfico
fig, axs = plt.subplots(1, 2, figsize=(16, 6))
# Tema del gráfico
sns.set_theme(style="whitegrid", palette="pastel")
# Histogramas de prestamos, financiados y pago mensual en axs[0]
sns.histplot(df_predict['monto_prestamo'], color='blue', label='Monto Préstamo', alpha=0.6, bins=50, ax=axs[0])
sns.histplot(df_predict['monto_financiado'], color='green', label='Monto Financiado', alpha=0.4, bins=60, ax=axs[0])
sns.histplot(df_predict['pago_mensual'], color='red', label='Pago anual', alpha=0.4, bins=50, ax=axs[0])
# Configuración de ejes y título
axs[0].set_xlabel('Monto')
axs[0].set_ylabel('Frecuencia')
axs[0].set_title("Distribución de Montos y Pagos")
# Crear el scatterplot en axs[1]
sns.scatterplot(data = df_predict, x='monto_prestamo', y= 'ingreso_anual',
ax=axs[1], hue= 'tasa_interes', palette="viridis", size='pago_mensual',
alpha=0.4, sizes=(20, 800))
# Ajustar los valores para que no muestre notación
axs[1].yaxis.set_major_formatter(ticker.FuncFormatter(lambda x, pos: '%1.0f' % x))
# Configuración de ejes y título para el gráfico de dispersión
axs[1].set_xlabel('Monto Préstamo')
axs[1].set_ylabel('Ingreso anual')
axs[1].set_title('Relación entre Monto de Préstamo e Ingreso Anual')
# Agregar la leyenda al subplot correspondiente
axs[0].legend()
axs[1].legend(loc='upper right')
# Mostrar gráfico
plt.show()

Distribución de Montos y Pagos (Histograma)
Relación Monto del Préstamo vs Ingreso Anual (Scatter Plot)
Análisis de Distribución de Crédito y Relación Deuda-Ingreso; Relación deuda-ingreso por años de experiencia (Boxplot)
# Crear gráfico
fig, axs = plt.subplots(1, 2, figsize=(16, 6))
# Tema del gráfico
sns.set_theme()
# Crear el scatterplot en axs[0]
sns.scatterplot(data = df_predict, x='monto_financiado', y= 'moras_ultimos_2_anios',
hue = 'relacion_deuda_ingreso', size ='anios_experiencia', ax=axs[0],
palette="viridis", alpha=0.3, sizes=(5, 400))
# Configuración de ejes y título
axs[0].set_xlabel('Monto financiado')
axs[0].set_ylabel('Moras en los ultimos 2 años')
axs[0].set_title("Distribución de uso de credito y saldos")
# Ajustar los valores para que no muestre notación
axs[0].yaxis.set_major_formatter(ticker.FuncFormatter(lambda x, pos: '%1.0f' % x))
#Rotar etiquetas del eje x
axs[0].set_xticklabels(axs[0].get_xticklabels(), rotation=45, ha='right')
# Agregar leyenda a la gráfico
axs[0].legend(loc='upper right')
# Crear el boxplot en axs[1]
sns.boxplot(data=df_predict, x= pd.cut(df_predict["anios_experiencia"], bins=[0, 3, 6, 10],
labels=["0-3", "4-6", "7-10"]), linewidth=2,
y='relacion_deuda_ingreso', hue='estado_prestamo', palette="viridis", ax=axs[1])
# Configuración de ejes y título
axs[1].set_xlabel('Años de experiencia')
axs[1].set_ylabel('Relación de deuda e ingreso')
# Obtener handles y labels después del boxplot
handles, labels = axs[1].get_legend_handles_labels()
axs[1].legend(handles, ["Deudor", "Al corriente"], title="Estado de prestamo", loc='lower right')
# Mostrar gráfico
plt.show()

Distribución de uso de crédito y moras (Gráfico de dispersión)
Relación deuda-ingreso por años de experiencia (Boxplot)
Guardado de CSV limpio
df_predict.to_csv('drive/MyDrive/Colab Notebooks/Análisis de riesgo en banco/df_lendingclub_limpio.csv', index=False)