¿Cómo predecir el riesgo de incumplimiento de pago de un cliente antes de otorgarle un crédito, utilizando sus características personales y financieras?
Objetivo: Predecir el nivel de riesgo crediticio de clientes a partir de sus características financieras y personales, utilizando modelos de clasificación.

- Importar las librerías usadas para generar este modelo. Se cargan los datos limpios al entorno de trabajo.
Librerías usadas
import pandas as pd
import numpy as np
from dateutil.relativedelta import relativedelta
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import matplotlib.ticker as ticker
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
Carga de datos
from google.colab import drive
drive.mount('/content/drive')
datos_respaldo = pd.read_csv('drive/MyDrive/Colab Notebooks/Análisis de riesgo en banco/df_lendingclub_limpio.csv')
datos = datos_respaldo.copy()
pd.options.display.max_columns = None
datos.head(3)

Análisis de DataFrame
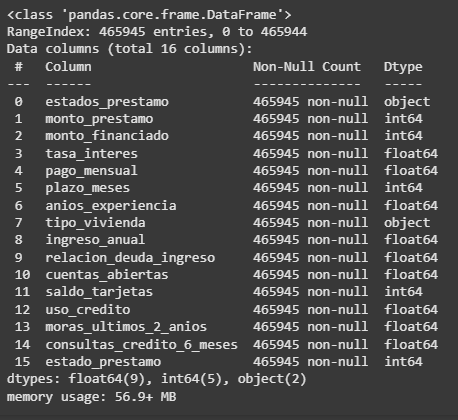
datos.info()
Creación de nuevas variables, codificación de datos categóricos, escalado de variables numéricas y tratamiento de valores nulos.
Codificación de Variables Categóricas
# Separar por categoría el tipo de vivienda
dummies = pd.get_dummies(datos['tipo_vivienda'], prefix='vivienda_').astype(int)
dummies.head(3)

# Como ya tenemos todas las variables como int o float, eliminar columnas categoricas
df_completo = pd.concat([datos, dummies], axis = 1)
df_completo.drop(['estados_prestamo', 'tipo_vivienda'], axis = 1, inplace = True)
df_completo.head(3)

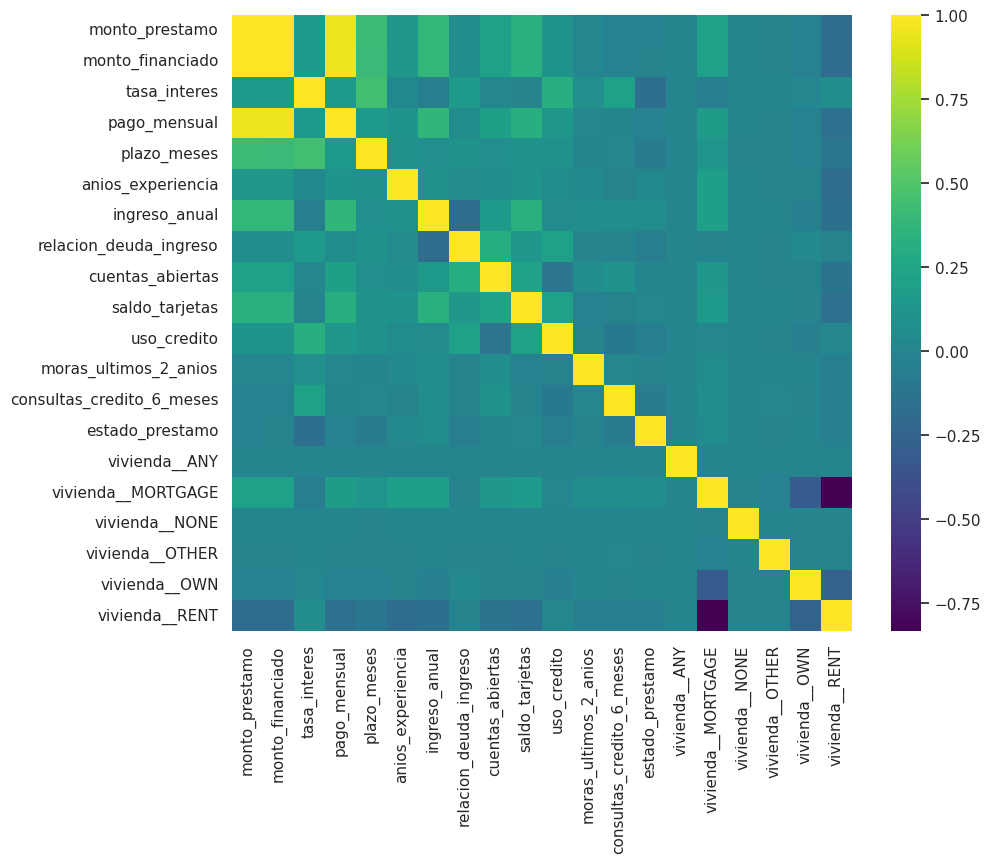
Correlación entre variables
# Calcular matriz de correlación
matriz_corr = df_completo.corr()
matriz_corr.head(3)

plt.figure(figsize=(10, 8))
sns.heatmap(matriz_corr, annot=False, cmap='viridis', fmt=".2f")
plt.show()
Entrenamiento y evaluación de distintos modelos de Machine Learning (Regresión Logística, Decision tree, Random Forest), con comparación de métricas de desempeño (accuracy, f1-score, etc.)
Normalizado de datos con MinMaxScaler
df_completo.columns
# Crear el objeto MinMaxScaler
scaler = MinMaxScaler()
# Normalizar los datos
df_normalizados = scaler.fit_transform(df_completo)
# Convertir el resultado a un DataFrame, especificando las columnas seleccionadas
df_normalizados = pd.DataFrame(df_normalizados, columns=df_completo.columns)
df_normalizados.head(5)

División del conjunto de datos (train-test split)
# Separación de los datosn en datos prueba y datos de muestra
x_entrenamiento, x_prueba, y_entrenamiento, y_prueba = train_test_split(
df_normalizados.drop('estado_prestamo', axis=1), # Variables independientes (X)
df_normalizados['estado_prestamo'], # Variable dependiente (y)
test_size=0.25, # 25% para prueba, 75% para entrenamiento
random_state=42 # Semilla para reproducibilidad
)
print(f'Tamaño "y_entrena" {y_entrenamiento.shape}\n Tamaño de "x_entrena" {x_entrenamiento.shape}')
Selección de modelo
# Selección del modelo de predicción
modelos = {
"Regresión Logística": LogisticRegression(),
"Árbol de Decisión": DecisionTreeClassifier(),
"Random Forest": RandomForestClassifier()
}
# Evaluar cada modelo en un pipeline
for nombre, modelo in modelos.items():
pipeline = Pipeline([
('escalado', StandardScaler()), # Paso 1: Escalar los datos
('modelo', modelo) # Paso 2: Modelo de ML
])
# Evaluar con validación cruzada
puntajes = cross_val_score(pipeline, x_entrenamiento, y_entrenamiento, cv=5, scoring='accuracy')
print(f"{nombre}: Precisión promedio = {puntajes.mean():.4f}")

Se usará "Regresión Logística" ya que obtuvo la mejor evaluación.
Ajuste de hiperparámetros
# Ajuste de hiperparametros
modelo = LogisticRegression(random_state=42)
parametros = {
'penalty': ['l1', 'l2'], # Regularización
'C': [0.1, 1.0], # Fuerza de regularización
'solver': ['liblinear', 'lbfgs'], # Algoritmo de optimización
'max_iter': [50, 100], # Número de iteraciones
'class_weight': ['balanced', None] # Peso de clases
}
# Creacion del estimador (GridSerch)
grid_search = GridSearchCV(modelo, parametros, cv=5, scoring='accuracy')
# Entrenamiento de grid_search
grid_search.fit(x_prueba,y_prueba)

Los mejores resultados se obtuvieron con: "C=0.1, max_iter=50, random_state=42, solver='liblinear'"
Entrenamiento del modelo con los parámetros ajustados
# Definiendo el final del modelo
modelo_final = LogisticRegression(C=0.1, max_iter=50, random_state=42, solver='liblinear')
# Entrenamiento de modelo
modelo_final.fit(x_entrenamiento, y_entrenamiento)

Evaluación del modelo
accuracy = modelo_final.score(x_prueba, y_prueba)
print(f"Accuracy del modelo: {accuracy:.2f}")

CONCLUSIÓN
El modelo desarrollado tiene como objetivo predecir el riesgo de crédito de un cliente a partir de sus características personales y socioeconómicas. Durante el proceso se realizó un análisis exploratorio de los datos, identificando las variables más relevantes y su relación con el riesgo crediticio.
Para mejorar el rendimiento del modelo, se aplicó la técnica de MinMaxScaler, con el fin de escalar los datos dentro de un rango definido y garantizar que todas las variables tuvieran un peso equitativo en el proceso de entrenamiento.
Los resultados obtenidos permiten clasificar de manera eficiente a los clientes según su nivel de riesgo, lo cual representa una herramienta útil para las instituciones financieras al momento de tomar decisiones sobre la aprobación o rechazo de créditos.
